Marketing Done Right.
-

Nexunom
Marketing firm providing different services and products.
-

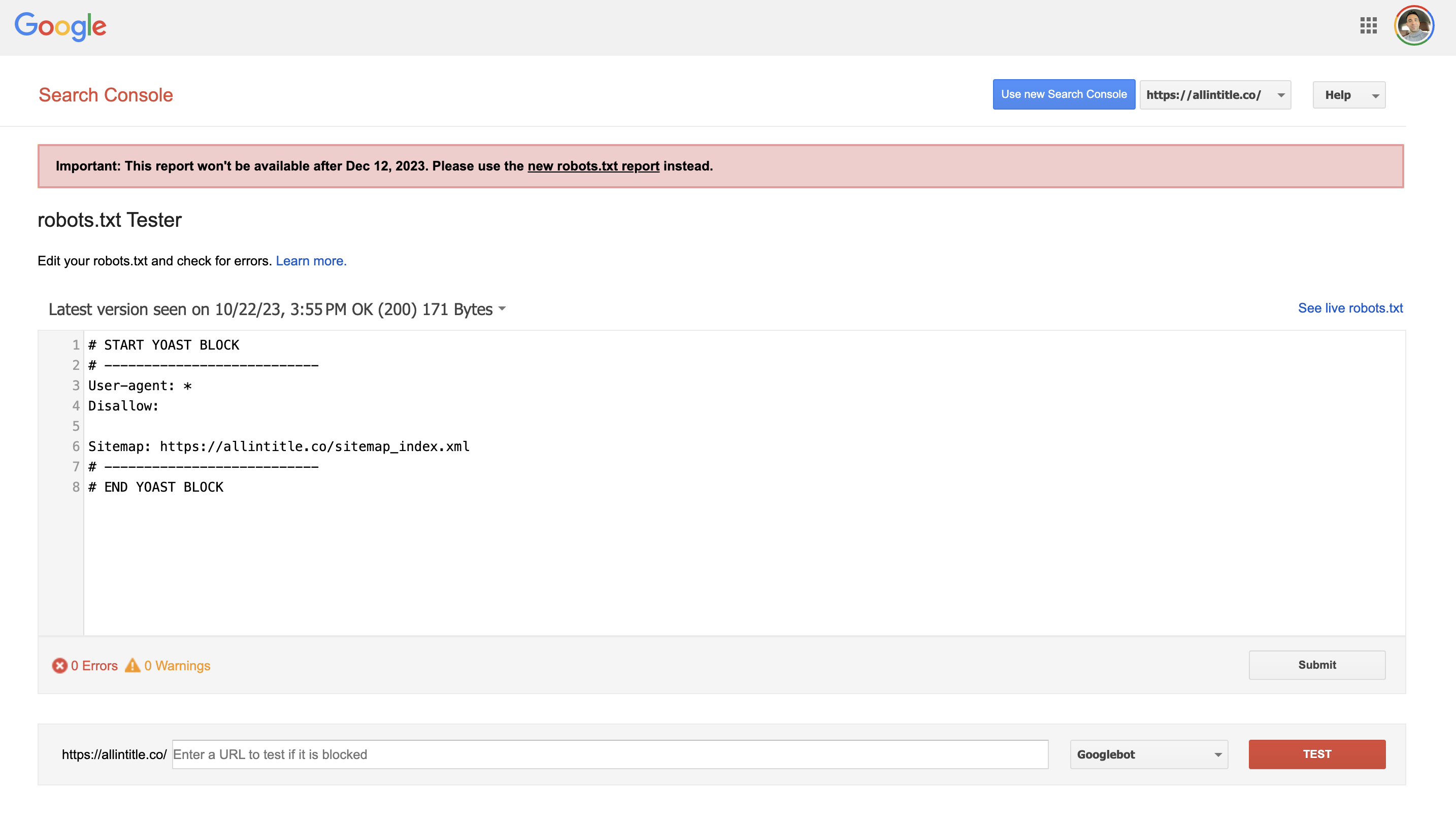
Allintitle
Premium keyword research tool and long-tail keywords finder.
-

Review Tool
Review management tool used by local businesses to get more reviews.
-

Tavata
Two-way text-based website chat widget with Pay-Per-Text payment structure.